關(guān)于我們
課工場簡介
服務(wù)條款
版權(quán)聲明
聯(lián)系我們
產(chǎn)品&服務(wù)
APP下載
優(yōu)質(zhì)資源
大咖團(tuán)隊(duì)
在線課程
周邊商城
幫助中心
新手上路
學(xué)習(xí)問題


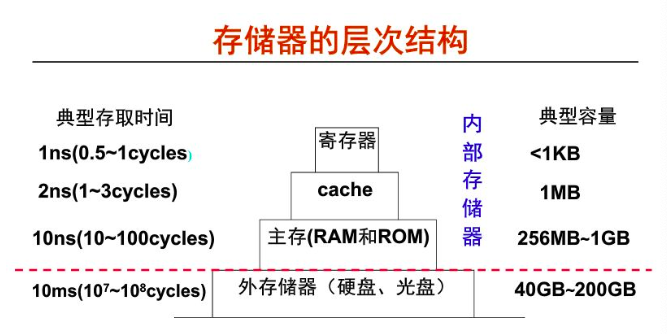
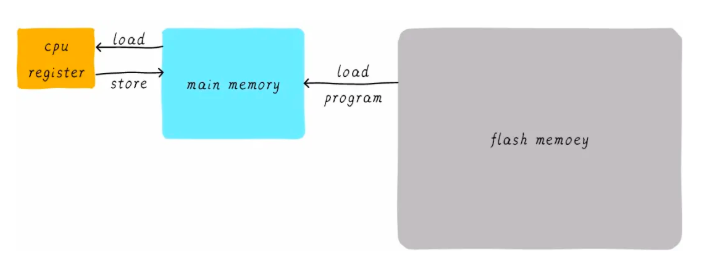
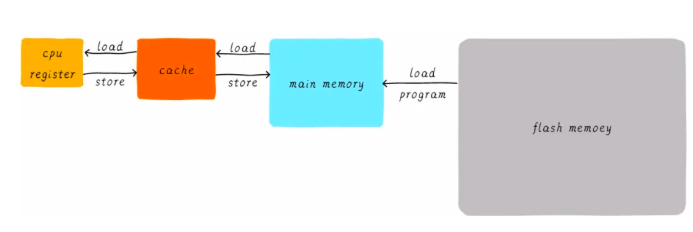
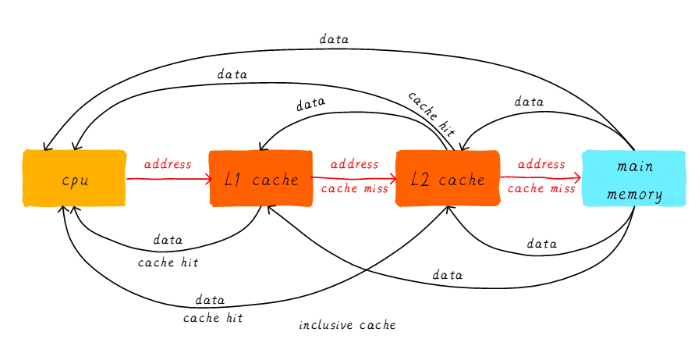







 京公網(wǎng)安備 11010802034997號
京公網(wǎng)安備 11010802034997號